
Types of Adversarial Attacks
Model Evasion Attacks
Summary: Tricking machine learning models into making incorrect predictions by exploiting specific vulnerabilities.

Defending Against Model Evasion Attacks
Defending against evasion attacks includes methods like adversarial training. Adversarial training is a way of training a model to be more resilient to small, targeted changes to its input. This can help the model to become more robust and less susceptible to these types of attacks. Additionally, other methods like adversarial detection and input validation can also be used to detect and mitigate the impact of these types of attacks. These methods can include techniques such as detecting changes in the input image, like adding noise or applying small transformations, or using input validation techniques to ensure that the input meets certain criteria, such as image size and resolution, before passing it to the model.Model Evasion Research Examples
DeepFool – The DeepFool paper, “DeepFool: a simple and accurate method to fool deep neural networks” presents a method for generating adversarial examples for deep neural networks (DNNs) by finding the smallest possible perturbation that can fool a DNN. The algorithm starts by initializing the adversarial example as the original input and then iteratively updates the perturbation until the DNN’s output is misclassified. The authors of the paper show that the DeepFool algorithm can fool a wide range of DNNs with high accuracy and low computational complexity, and the adversarial examples generated by the algorithm are often imperceptible to humans. Audio Adversarial Examples – The paper “Audio Adversarial Examples: Targeted Attacks on Speech-to-Text” describes a method for creating targeted audio adversarial examples that can fool automatic speech recognition systems. The authors use an iterative optimization-based attack to produce audio waveforms that are over 99.9% similar to the original but transcribe as any phrase they choose, and demonstrate a 100% success rate when applied to Mozilla’s implementation of DeepSpeech. This work highlights the feasibility of these types of attacks and the need for further research in this area to develop defences against them.Poisoning Attacks
Summary: Poisoning a machine learning model’s training data with malicious examples to manipulate behaviour.
Poisoning attacks are a type of malicious attack in which an attacker intentionally injects malicious data into the training set of a machine learning model. This can cause the model to learn from the poisoned data and make incorrect predictions. The attacker may do this to cause the model to misclassify a specific image or to cause other types of errors. For example, an attacker could manipulate the labels of images in a training set in order to cause a model to misclassify a specific image. If the attacker wants a model to misclassify a picture of a stop sign as a speed limit sign, they could change the label of a stop sign in the training set to a speed limit sign. This would cause the model to learn that stop signs are speed limit signs, and it would make that mistake when it sees a stop sign in the future.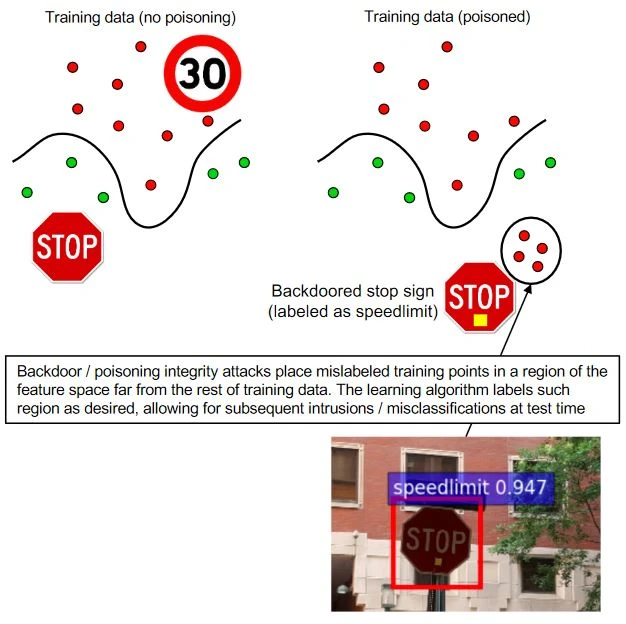
Defending Against Poisoning Attacks
Defending against poisoning attacks requires a multi-faceted approach, including techniques such as:- Training models with differential privacy, which is a technique that adds noise to the training data in order to make it difficult for an attacker to infer information about any individual data point.
- Using strong regularization techniques to prevent overfitting to the poisoned data.
- Monitoring the distribution of the input data during training to detect any unusual patterns that may indicate poisoned data.
- Using data validation and outlier detection techniques to detect and remove any poisoned data from the training set.
- Continuously retraining models with fresh data to reduce the impact of any poisoned data that may have been used in the past.
Poisoning Attack Research Example
Bypassing Backdoor Detection Algorithms in Deep Learning – This paper, “Bypassing Backdoor Detection Algorithms in Deep Learning,” explores the susceptibility of deep learning models to adversarial manipulation of their training data and input samples, specifically in the form of backdoors. Backdoors are malicious features implanted by attackers that cause the model to behave in a specific way when the input contains a specific trigger. Detection algorithms aim to identify these backdoors by identifying the statistical difference between the latent representations of adversarial and clean input samples in the poisoned model. However, the paper presents an algorithm that can bypass existing detection algorithms by using an adaptive adversarial training algorithm that optimizes the original loss function of the model and maximizes the indistinguishability of the hidden representations of poisoned data and clean data.Inference Attacks
Summary: Gaining access to sensitive information stored in a ML model through indirect methods such as analyzing its predictions or input-output behaviour.
Inference attacks are a type of malicious attack in which an attacker aims to extract sensitive information from a machine learning model by analyzing its behaviour. The attacker may use various techniques to do this, such as analyzing the model’s prediction probabilities or studying the model’s internal structure. For example, an attacker could use a model’s prediction probabilities to infer whether an individual is included in the training dataset. If a model is trained on a dataset of individuals, then it will typically make high-confidence predictions when given one of these individuals. This is due to the model overfitting on its training data. An attacker can then exploit this information by probing the model with various perturbations of the data representing this individual, then watching how the model’s confidence scores change. An attacker can then infer training dataset membership from these observations.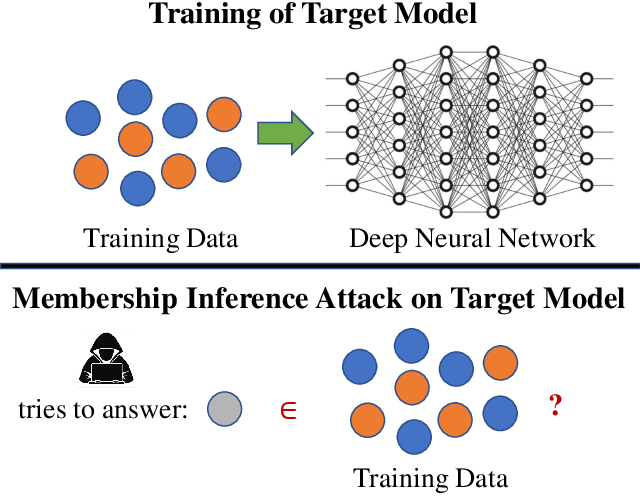
Defending Against Membership Inference Attacks
- Data sanitization: This involves removing or altering sensitive information from the training data set, making it difficult for an attacker to infer membership from the model’s behaviour.
- Model perturbation: This involves adding noise to the model’s parameters or output, making it difficult for an attacker to infer membership from the model’s behaviour.
- Subsampling: This involves training the model on a subset of the data, rather than the entire data set, making it difficult for an attacker to infer membership from the model’s behaviour.
- Access control: This involves limiting access to the model or data set, so that only authorized parties can perform membership inference attacks.
- Differential Privacy (DP) : This is a mathematical framework that provides provable privacy guarantees for the data set. DP techniques can be used to ensure that the model’s behaviour does not reveal information about the membership of individual samples in the training data set.
Membership Inference Attack Research Example
Model Extraction Attacks
Summary: Stealing a ML model’s parameters or architecture through direct methods such as model cloning or reverse-engineering.
Model extraction attacks, also known as model stealing attacks, involve an attacker stealing a trained machine learning model. This is typically done by reverse engineering the model, which involves analyzing the model’s structure and parameters in order to understand how it works. Once the attacker has a copy of the model, they can use it for a variety of malicious purposes. For example, an attacker could use a stolen model to make predictions, steal sensitive information, or even retrain the model for their own purposes. For instance, if an attacker is able to steal a model that has been trained on sensitive customer data, they could use the model to make predictions about the customers or even retrain the model using the stolen data to create a new model for their own use.
Defending Against Model Extraction Attacks
Defending against model extraction attacks requires a multi-faceted approach, including techniques such as:- Obfuscation: This involves making the model architecture and parameters difficult to understand, so that it is difficult for an attacker to extract useful information from the model.
- Watermarking: This involves embedding a unique identifier or signature into the model, so that it can be traced back to the original source if it is extracted by an attacker.
- Model distillation: This is a technique where a smaller, simpler model is trained to mimic the behaviour of a larger, more complex model. The smaller model is less valuable to an attacker, and it can also be more easily protected with obfuscation or watermarking techniques.
- Input transformations: This involves transforming the input data before it is passed to the model, such as adding random noise or encrypting the data. This makes it difficult for an attacker to extract useful information from the model’s behaviour.
- Model Ensemble : This is a method of creating a set of different models that are trained on the same data set, and then combining their predictions to make a final decision. This can make it more difficult for an attacker to extract a single, useful model from the ensemble.
- Secure Multi-Party Computation (SMPC): This is a cryptographic technique that allows multiple parties to perform computations on data without revealing the data to the other parties. SMPC can be used to protect the model from being extracted by an attacker.
Model Extraction Attack Research Example
DeepSniffer – The paper “DeepSniffer: A Learning-based Model Extraction Framework for Obtaining Complete Neural Network Architecture Information” proposes a framework called DeepSniffer to obtain complete neural network model architecture information without any prior knowledge of the victim model. Previous methods of extracting model architecture information have limitations such as requiring prior knowledge of the victim model, lacking robustness and generality, or obtaining incomplete information. DeepSniffer is robust to architectural and system noise introduced by complex memory hierarchies and diverse runtime system optimizations. It works by learning the relation between extracted architectural hints, such as volumes of memory reads/writes obtained by side-channel or bus snooping attacks, and the model’s internal architecture. The authors demonstrate the effectiveness of DeepSniffer by using it on an off-the-shelf Nvidia GPU platform running a variety of DNN models, and show that it improves the adversarial attack success rate from 14.6% to 25.5% (without network architecture knowledge) to 75.9% (with extracted network architecture).Adversarial ML Research Tools
To conduct AML research, researchers rely on a variety of tools to generate, analyze, and defend against adversarial examples and attacks. In this blog section, we will explore some of the most commonly used tools in the AML research community. These tools can be used to generate adversarial examples, evaluate a model’s robustness, and develop defenses against attacks.
Adversarial Research Toolkit – IBM
The Adversarial Robustness Toolbox (ART) is an open-source library developed by IBM that allows users to test and improve the robustness of machine learning models against adversarial attacks.
ART provides a comprehensive set of tools for evaluating a model’s robustness, including pre-trained models, attack methods, and metrics for measuring the effectiveness of these attacks. It supports several popular deep learning frameworks, including TensorFlow and Keras, and can be easily integrated into existing machine learning pipelines.
One of the key features of ART is its support for a wide range of attack methods, including both white-box and black-box attacks. ART also includes a library of pre-trained models that can be tested to evaluate their susceptibility to attack. In addition to its attack capabilities, ART also includes a set of metrics for evaluating a model’s robustness. These metrics include standard measures such as the misclassification rate, as well as more advanced metrics such as the average confidence of an attack.
Overall, the Adversarial Robustness Toolbox is a valuable resource for anyone working on machine learning models, as it allows them to test and evaluate the robustness of their models against a wide range of adversarial attacks.
TextAttack – QData

TextAttack is an open-source framework developed for natural language processing (NLP) models that allows users to test and improve the robustness of their models against adversarial attacks. It provides a comprehensive set of tools for evaluating a model’s robustness, including attack methods, metrics, and pre-trained models.
One of the unique features of TextAttack is its support for a wide range of NLP tasks, including text classification, machine translation, and language modeling. It also supports several popular deep learning frameworks and libraries, such as PyTorch, TensorFlow and Hugging Face’s Transformers.
TextAttack includes a variety of attack methods, including both white-box and black-box attacks. TextAttack also provides several pre-trained models that can be used to test the robustness of a model. In addition to its attack capabilities, TextAttack also includes a set of metrics for evaluating a model’s robustness. These metrics include standard measures such as the misclassification rate, as well as more advanced metrics such as the semantic similarity between the original and adversarial text.
Overall, TextAttack is a powerful tool for NLP researchers and practitioners, as it allows them to evaluate the robustness of their models against a wide range of NLP specific attacks that are not present within other AML toolkits.
CleverHans – CleverHans Lab
![]()
Cleverhans is an open-source Python library for adversarial machine learning. It provides a variety of tools for crafting adversarial examples and evaluating models’ robustness to them.
Cleverhans provides several methods for crafting adversarial examples, including the Fast Gradient Sign Method (FGSM) and the Basic Iterative Method (BIM). It also includes a variety of pre-built attacks, such as the Carlini-Wagner attack and the DeepFool attack. These methods can be applied to a wide range of models, including those built using TensorFlow and Keras.
In addition to crafting adversarial examples, Cleverhans provides tools for evaluating a model’s robustness. For example, it includes a method for estimating the model’s “adversarial accuracy”, which is the proportion of adversarial examples that are correctly classified. It also provides a way to measure the “transferability” of adversarial examples, which is the extent to which an adversarial example crafted for one model can fool another model.
Cleverhans also includes a variety of defense mechanisms that can be used to improve a model’s robustness to adversarial examples. These include adversarial training, which involves training a model on a dataset that includes adversarial examples, and ensemble adversarial training, which involves training multiple models on different subsets of the training data.
Cleverhans is a powerful tool for anyone interested in adversarial machine learning and evaluating the robustness of models. It is well-documented and easy to use, making it accessible to researchers and practitioners at all levels of experience.
